https://x.com/bibryam/status/2020091167522844971?s=12
https://charap.co/on-metastable-failures-and-interactions-between-systems/
Old one: https://charap.co/metastable-failures-in-the-wild/
Takeaway
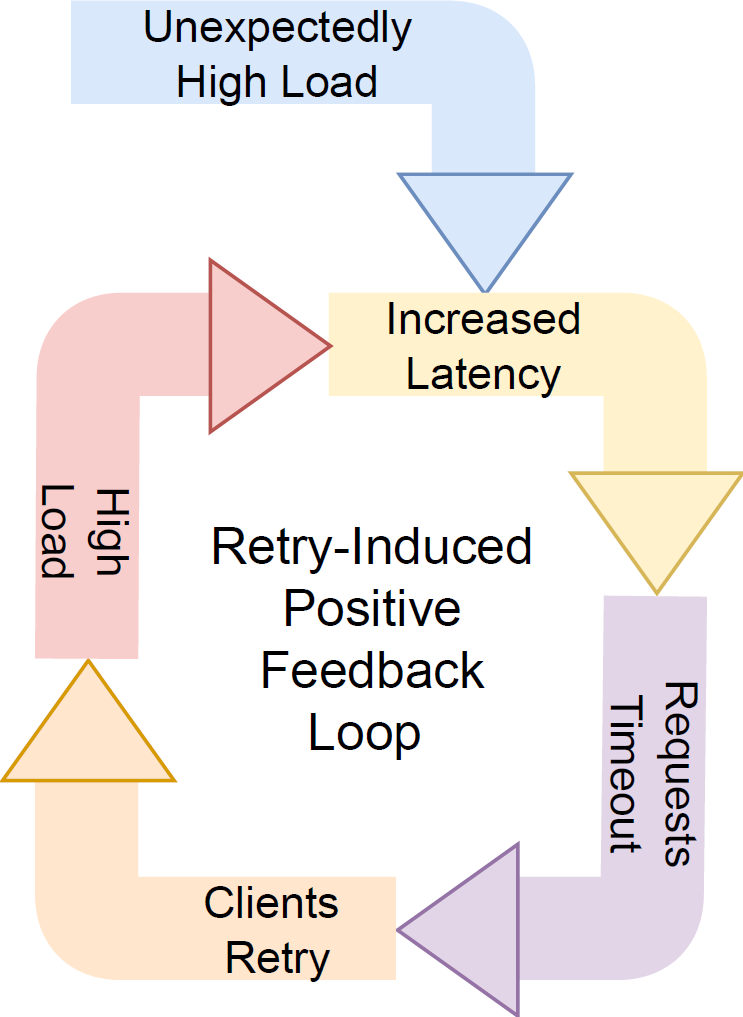
- From the old one: 什么是 meta-stable failure
- 复杂系统中, 系统在稳态, 但是
- 通过一个 Trigger
- 可能是流量 spike
- 可能是局部宕机, 容量下降
- 某个错误配置
- 某个逻辑 hidden slow path 被激活
- 和一个放大机制 Amplification
- 比如说重试风暴
- 系统进入一种状态
- 即使修复了 root cause, 系统也无法恢复
- 稳定的错误态
- 预防措施
- 留有冗余容量
- Load Shedding, 在 app 机制设计上降级/丢掉不重要的请求
- PS: 和 high available 其实有冲突, 工程实现上感觉可以扩容或者分级
- 注意 Human Factor
- Friday Release
- Bad Configuration
- Buggy code
- fix-to-break: some “solution” leads more breaks
- From the new one:
- New Concept:
- Actions, States, and Signals
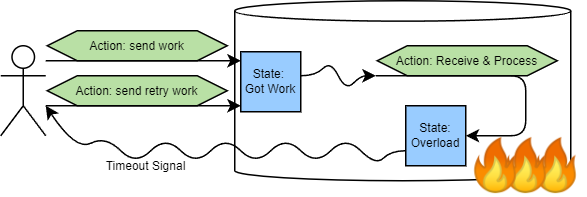

- Action State Signal 螺旋升天
- 三种 solution:
- Avoid interactions between components
- 减少相互耦合
- 理论可行, 实际工程比较困难
- batched request
- cache
- read-write split
- event driven / queue + pub/sub
- Avoid taking actions to create positive feedback
- 限制 retry 次数, exp backoff
- rate limit
- retry budget, retry 不能超过正常流量的一定比例
- 特定情况下, 需要 fail fast
- 适用于 AP 系统, 不适用于 CP 系统
- Avoid ambiguous signals
- 多个 signal 协同判断
- 需要运维信息回馈 dev
- Avoid interactions between components